


Who's That Singing?

When people hear mothershout tracks, I often get asked who’s that singing? The technical answer is, as I’ve written on the About page here on Substack, is that they’re synthetic voices, produced by a rather amazing bit of software called Synthesizer V from a Japanese company called Dreamtonics. But I feel the need to expand a bit on that.
Dreamtonics and other voice providers like to use the term “AI” to describe their voices. This is probably good marketing, but it’s potentially really misleading, because the term AI is not well defined, and the whole Rise Of ChatGPT and generative image creation has given many people a false impression of what AI is and can do. I’ve had comments like oh, so you just give them the words and they do all the rest.
No. Not at all. The AI in these voices does one thing only: it’s learned a limited amount about how an actual human sings:
How a human voice moves from one note to another.
In some cases, how a singer breathes before and after a note.
How their voice sound changes depending on volume and tone.
Also, I’m not at all interested in having AI generate music for me. I do this stuff because I enjoy it. I like the challenges of writing and recording and mixing, and I don’t see any value in having an automated system take that away. I wouldn’t use any synthetic voice that was smarter and did more by itself.
So what does the musician (me) have to do to get a good performance out of a synthesized voice? Well…
I write all the music; figure out the notes that will be sung, for the lead voice(s) and the harmonies.
I choose the key to make sure the vocal melodies are in the singers’ ranges; these voices have the same limitations as humans and sing better in some keys than others. Get too high or too low and, like a human, they’ll struggle.
I have to write singable lyrics. The voices can sing faster than a human, but they have the same problems with tricky syllables that don’t follow each other well.
I carefully assign the words to the vocal melody notes, and pick the specific phonemes (syllable sounds) that are sung. For example, the word love might be phonetically spelled l ah v. But in the choruses of Some Say Love it’s l ah ə v to fit the way the word is split over two (or more) notes (that ə is a schwa or “uh” sound).
I have to choose the voice mode. Should the singer be belting out a phrase, or singing softly? Chest or head voice? This can vary within a verse, within a phrase and even within a long note, and it’s all adjusted manually.
I have to tweak many of the phonemes. As well as the subtle differences between aa (the letter a in palm) and ae (the letter a in bat), the voices have different versions of each phoneme. And sometimes the duration or strength or microsecond timing of a phoneme needs to be tweaked to hit the beat or make the word sound right.
A key point is that these voices have absolutely no understanding of what the words mean; I have to put all the expression in.
Here’s an example of doing this sort of work in the Synthesizer V interface. This is the line some say love from the song with the same name.

The green blocks are the notes. This is what’s often called a piano roll style of interface; the notes line up with the piano keys on the left and play from left to right (like an old-style player piano). You can see some of the words inside the green blocks, and above the blocks are the phonemes; the actual syllables that are sung. For the word love I’ve specified the exact phonemes used on each note. And between say and love I added an extra note with the phoneme ax (the schwa or “uh” sound) so that the words sung are more like some say-uh luh-uhv.
Here’s another example:
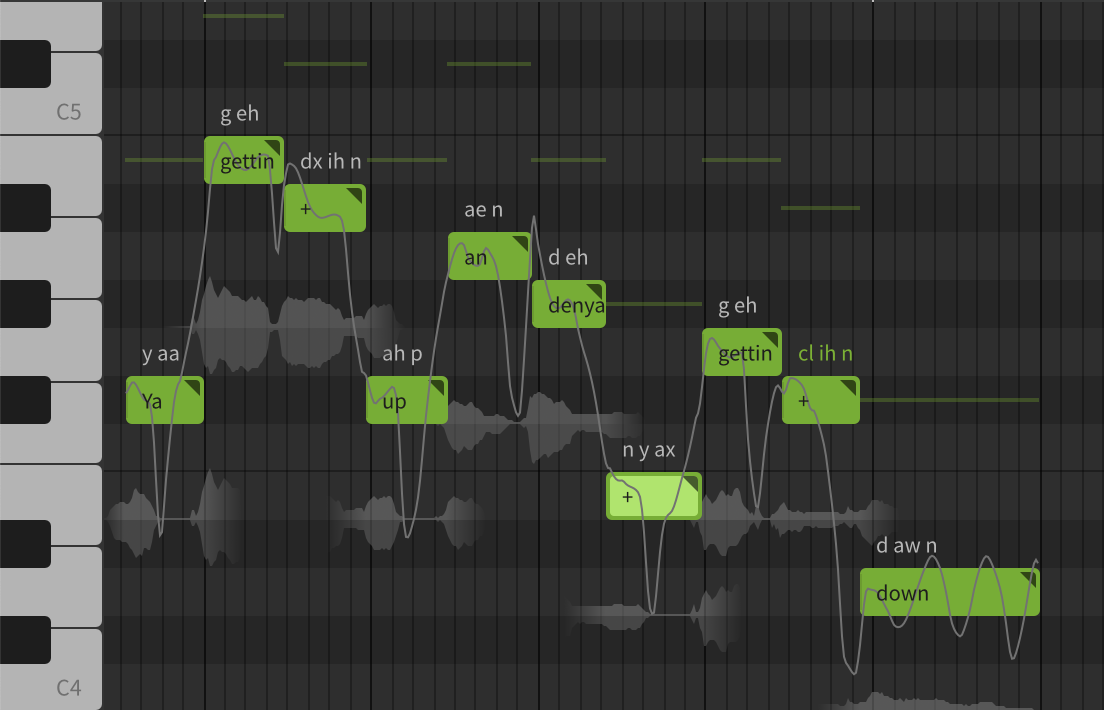
This is the line you’re getting up and then you’re getting down from the first verse. But the words set up for the singer are more like ya gettin up an denya get’in down. That’s closer to what a human would really sing, and to know that you have to try singing it, and then go and tweak each word.
And that’s not all. Here’s an example of tweaking some of the parameters for one single note (the last the in the line nothing but a thrill in the night in the first chorus):

The ax phoneme is ax (the schwa “uh” sound again) rather than any other type of “a”, and it’s been shortened to 65% of the default length so that the whole word can be sung quickly, to let the following word night land on the beat.
I think the best way to think of these voices is… just like any other synthesized instrument. A musician needs to learn how to play them, and then they need to be played carefully to get the best performance. And that’s a lot of slow, painstaking work.
So no, not the Rise Of The Machines. Not yet, anyway.